История страницы
Классифицировать текст Версия 1 (python)
Группа "Robin AI", подгруппа "Машинное обучение"
...
Описание
Действие определяет класс, к которому относится текст, на основе обученной модели классификации, т.е. показывает вероятность отношения текста к определенному классу, соответствующему рубрике на основе обученного метода классификации.
...
Параметры
Входные параметры
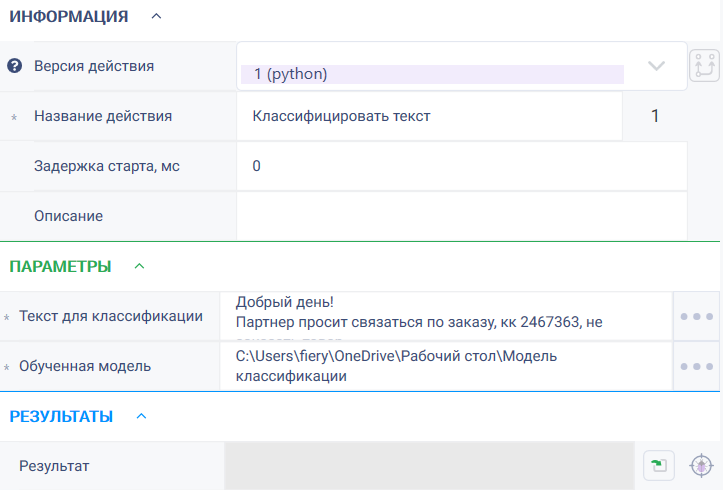
- Текст для классификации - текст, класс которого необходимо определить. Язык может быть любой. Если будет язык отличный от языка обучающей выборки, то процент определения класса будет близким к нулю.
- Обученная модель - путь к папке, которая содержит обученную модель классификации. В папке должно содержаться два файла: machine_model.pkl и tfidf_model.pk. Отсутствие какого-то файла или изменение имени папки на другое может привести к ошибке.
Выходные параметры
- Результат - словарь, где ключ - название класса, а значение - процент вхождения в данный класс. Сортировка в словаре производится по проценту вхождения в класс.
...
1.В папке, которая содержит обученную модель, должно содержаться два файла. Файлы предоставляются заказчику по требованию. Данные файлы представляют из себя запакованную модель машинного обучения.
2.Если какого-то файла нет/другое название, то это приведет к ошибке при работе действия.
...
- Перенести действие "Классифицировать текст" на рабочую область.
- Заполнить параметры действия "Классифицировать текст".
В поле "Текст для классификации" указать следующий текст:
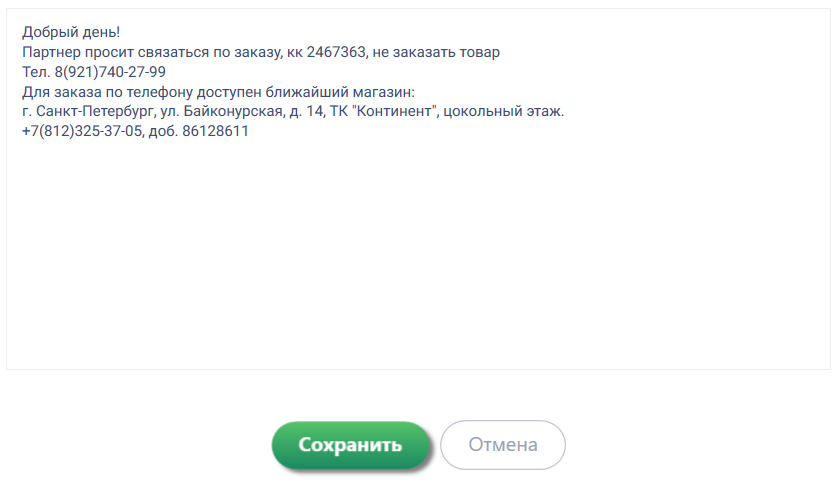
3. Указать путь к папке, которая содержит обученную модель.
4. Нажать на кнопку "Старт" в верхней панели.
...
Программный робот отработал успешно. Получен словарь , где Ключ - рубрика, а Значение - процент вхождения в данную рубрику. Сортировка в словаре по проценту вхождения в рубрику.
В результате получился словарь с названием категории и с точностью принадлежности к данной категории.
При необходимости получения рубрики к которой текст относится в наибольшей степени необходимо воспользоваться действием "Получить коллекцию ключей", потому что в значениях % указаны, а сами рубрики-категории в ключах. Далее, нужно получить коллекцию ключей и нулевой элемент этой коллекции - это та рубрика, к которой скорее всего относится текст (действие "Получить значение по индексу").
Обзор
Инструменты контента